“
Massenverfahren gelten als ideal für Automatisierung — weil sich die Fälle ähneln.
Was dabei übersehen wird: Jeder Fall trägt individuelle Datenpunkte, und das institutionelle Wissen über Gegner, Richter und Argumentationslinien steckt häufig in abgeschlossenen Akten, die kein System zusammenführt.
Es gibt eine Kategorie von Rechtsstreitigkeiten, die auf den ersten Blick nach dem idealen Automatisierungsfall aussieht. Die Rechtsgrundlage ist in engen Grenzen definiert. Die Anspruchshöhe ist berechenbar. Die Prozessstruktur ist standardisiert. Hunderte, manchmal tausende Fälle folgen demselben Grundmuster.
Trotzdem scheitern die meisten Automatisierungsversuche in genau diesem Umfeld.
Das erste Problem: Fristen stecken in Dokumenten, nicht in Systemen.
Das zweite Problem: Erkenntnisse aus abgeschlossenen Fällen sind nicht zugänglich.
Das dritte Problem: Schriftsätze entstehen aus dem Gedächtnis erfahrener Sachbearbeiter — nicht aus einer reproduzierbaren Logik.
Dieser Beitrag beschreibt, wie DEPLAW diese drei Probleme strukturell löst.
01
Das Grundproblem
Warum scheinbar einfache Massenverfahren komplex sind.
Die Homogenität von Massenverfahren ist eine Illusion.
In der Praxis ist jeder Fall individuell: andere Datenpunkte, andere Gegenpartei-Konstellationen, andere Fristen, andere Bearbeitungshistorien.
Was identisch ist, ist das Regelwerk — nicht der Fall. Das erzeugt ein spezifisches operatives Muster:
Die Routinearbeit ist hoch, die Fehlertoleranz ist niedrig, und das relevante Wissen ist ungleich verteilt.
Der erfahrene Sachbearbeiter kennt die Muster. Er weiß, welche Argumentation bei welchem Gericht zieht. Er weiß, welcher Gegenseitenanwalt welche Strategie verfolgt. Dieses Wissen ist aber nicht im System — es ist in ihm.
Wenn er krank ist, geht das Wissen nicht raus. Wenn er die Kanzlei verlässt, geht es verloren. Und selbst wenn er da ist, kann er es nur auf die Fälle anwenden, die er persönlich kennt — nicht auf alle hundert, die gerade gleichzeitig bearbeitet werden.
Die drei strukturellen Schwachstellen in Massenverfahren |
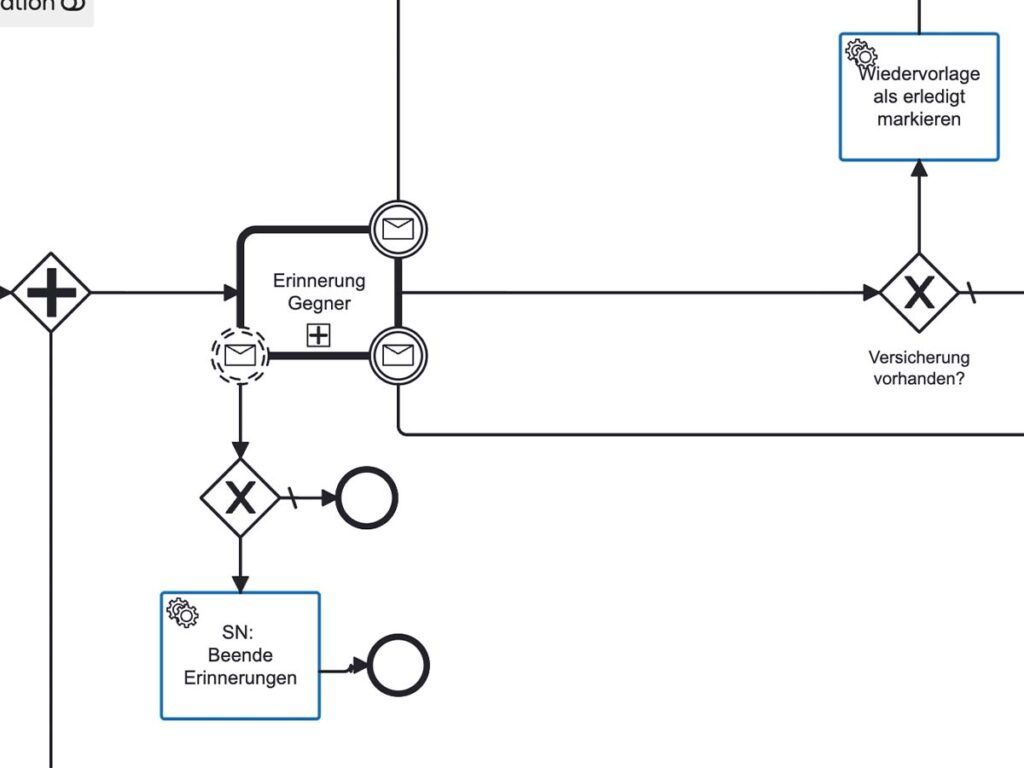
Schwachstelle 1 — Fristerkennung: Fristen aus eingehenden Dokumenten werden manuell gelesen, manuell eingetragen, manuell als Wiedervorlage gesetzt. Jeder dieser Schritte ist fehleranfällig — und bei hohem Eingangsvolumen auch kapazitätslimitierend. |
Schwachstelle 2 — Wissenssilos: Erkenntnisse aus abgeschlossenen Verfahren — welche Argumente haben gewirkt, welche nicht, welche Muster zeigt die Gegenseite — sind nicht systematisch verfügbar. Sie stecken in Akten, in E-Mails, im Kopf des zuständigen Sachbearbeiters. |
Schwachstelle 3 — Schriftsatz-Improvisation: Schriftsätze entstehen aus alten Vorlagen, aus Kopieren und Anpassen, aus dem Formulierungsgedächtnis der Verfasser. Konsistenz und Qualität hängen von der Person ab — nicht von der Infrastruktur. |
Diese drei Schwachstellen existieren nicht unabhängig. Sie verstärken sich gegenseitig. Wer Fristen manuell erfasst, hat keine Zeit für strategische Fallanalyse. Wer Schriftsätze manuell erstellt, kann das institutionelle Wissen aus vergangenen Verfahren nicht systematisch einbinden. Das Ergebnis ist ein Betrieb, der unter Kapazitätsdruck läuft und nicht skaliert.
02
Lösung 01
Automatische Fristen-Extraktion
Das strukturell sauberste Fundament einer Massenverfahrens-Automatisierung ist der Dokumenteneingang.
Alles, was danach passiert, hängt davon ab, ob eingehende Dokumente sofort, vollständig und fehlerfrei verarbeitet werden.
In DEPLAW beginnt dieser Prozess automatisch — unabhängig davon, über welchen Kanal das Dokument eingeht.
01 Kanalübergreifender Eingang [Posteingang · beA] Dokumente kommen per beA, E-Mail, Upload oder Scan. Der zentrale Posteingang von DEPLAW bündelt alle Kanäle in einer Oberfläche. OCR macht gescannte Dokumente maschinenlesbar. Kein manuelles Öffnen verschiedener Postfächer. |
02 Klassifizierung und Kontextbestimmung [KI-Klassifizierung] Die KI-Funktionen von DEPLAW erkennen den Dokumenttyp. Welche Art von Schreiben ist das? Welchem Verfahrensschritt entspricht es? Diese Klassifizierung bestimmt, welche Datenpunkte extrahiert werden müssen und welcher Workflow-Ast ausgelöst wird. |
03 Strukturierte Datenextraktion [Datenextraktion] Die Datenextraktion von DEPLAW liest die relevanten Datenpunkte aus dem Dokument: Fristen — gerichtlich, gesetzlich, vertraglich —, Parteienbezeichnungen, Aktenzeichen, Streitwert, Verfahrensstadium. Diese Daten werden direkt als strukturierte Variablen in der Akte gespeichert. Kein manuelles Eintippen. |
04 Automatische Wiedervorlagen-Setzung [Wiedervorlagen] Jede extrahierte Frist wird sofort als Wiedervorlage angelegt — mit dem richtigen Datum, dem richtigen Bearbeiter, dem richtigen Kontext. Die Wiedervorlagen-Funktion stellt strukturell sicher, dass keine Frist vergessen werden kann. Nicht durch individuelle Aufmerksamkeit — durch Systemlogik. |
05 Eskalation bei kritischen Fristen [Workflow-Editor] Wenn eine Frist besonders kurzfristig ist oder der zuständige Bearbeiter bereits ausgelastet ist, greift die im Workflow-Editor definierte Eskalationslogik automatisch. Das System informiert die Teamleitung und schlägt eine alternative Zuordnung vor. |
Das Ergebnis: Ein eingehendes Dokument ist innerhalb von Minuten klassifiziert, die relevanten Daten sind in der Akte, die Frist ist gesetzt. Bevor der Sachbearbeiter das Dokument öffnet, weiß er bereits, was er hat — und wann er handeln muss.
03
Lösung 02
Erkenntnisse fallübergreifend systematisch nutzen
Das zweite Strukturproblem ist das, das in der Legal-Tech-Diskussion am seltensten adressiert wird — obwohl es in Massenverfahren strategisch entscheidend ist.
- Jedes abgeschlossene Verfahren enthält Erkenntnisse:
- Welche Argumentation hat vor welchem Gericht funktioniert?
- Welche Einwände hat die Gegenseite typischerweise gebracht?
- Wie ist ein bestimmter Gegneranwalt vorgegangen — und was hat ihn in der Vergangenheit gestoppt?
Diese Informationen sind Gold. Aber sie liegen in abgeschlossenen Akten, geordnet nach Aktenzeichen, nicht nach ihrer strategischen Verwertbarkeit.
Institutionelles Wissen aus abgeschlossenen Verfahren ist das wertvollste Kapital in der Massenbearbeitung. In den meisten Betrieben ist es vollständig unzugänglich. – Tim Platner, Geschäftsführer der Legal Data Technology GmbH |
DEPLAW löst das über die Beteiligtendaten-Funktion. Jede Partei, jeder Gegneranwalt, jedes Gericht, jede relevante Instanz ist ein strukturierter Datensatz — verknüpft mit allen Verfahren, in denen diese Person oder Institution vorkommt.
Was strukturierte Beteiligtendaten in Massenverfahren leisten |
Fallübergreifendes Profil von Verfahrensbeteiligten: Wie viele Verfahren gibt es mit dieser Gegenpartei oder diesem Anwalt? Welche Argumentationsmuster wurden eingesetzt? In welchen Konstellationen gab es Erfolg — in welchen nicht? |
Gerichts- und Rechtsprechungsverknüpfung: Relevante Urteile können als Beteiligte mit Verfahren verknüpft werden. Wenn ein Gericht in einem früheren Verfahren zu einer bestimmten Frage entschieden hat, ist diese Entscheidung als Referenz beim nächsten gleichgearteten Fall sofort abrufbar. |
Strategischer Erkenntnistransfer: Wenn Sachbearbeiter A ein erfolgreiches Argument in einem Verfahren erarbeitet hat, ist dieses Argument über die Beteiligtendatenbank für Sachbearbeiter B beim nächsten verwandten Verfahren zugänglich — ohne Briefing, ohne Suche. |
Mustererkennung bei Gegenparteien: Wenn dieselbe Gegenpartei in vielen Verfahren mit derselben Strategie vorgeht, wird das sichtbar. Das erlaubt proaktive Vorbereitung statt reaktive Reaktion. |
Rechtsprechungsintegration: Über die Beteiligtenfunktion lassen sich Gerichtsentscheidungen thematisch und kontextuell mit laufenden Verfahren verknüpfen — nicht als Dokumentenablage, sondern als strukturierte Referenz im Arbeitskontext. |
Was das in der Praxis bedeutet: Ein Sachbearbeiter, der einen neuen Fall zur Bearbeitung erhält, sieht sofort die relevante Verfahrenshistorie — welche Konstellationen es mit dieser Gegenpartei bereits gab, welche Entscheidungen einschlägig sind, was in der Vergangenheit funktioniert hat und was nicht. Diese Information ist nicht in seiner Erinnerung. Sie ist im System.
04
Lösugn 03
Schriftsätze auf den Punkt: Textbausteine, KI & Rechtsprechung
Der dritte Baustein ist der sichtbarste — und der, der in der Diskussion über KI im Recht am häufigsten vereinfacht wird.
Die vereinfachte Version lautet:
KI schreibt den Schriftsatz. Prompt rein, Schriftsatz raus. Das ist technisch möglich. Aber es ist auch juristisch problematisch — weil allgemeine Sprachmodelle keinen Zugriff auf die Fallakte haben, keine Kenntnis der kanzleispezifischen Argumentationsstandards und keine Garantie für rechtliche Präzision in den kritischen Formulierungen.
Was funktioniert, ist ein System aus drei Schichten, die zusammenwirken.
Schicht 1: Feingranulare Textbausteine als Qualitätsfundament
Die Textbaustein-Funktion von DEPLAW erlaubt es, juristische Formulierungen auf einem Detailgrad zu standardisieren, der weit über einfache Vorlagen hinausgeht. Nicht Gesamttexte — einzelne Formulierungsbausteine für spezifische Argumentationskonstellationen, Einwendungsstandards, Standardverweise auf Rechtsprechung, Schlussformeln je nach Verfahrensstadium.
Diese Bausteine sind zentral verwaltet. Das bedeutet:
Wenn ein Urteil eine bestehende Formulierung veraltet macht oder die Kanzlei ihre Argumentationsstrategie anpasst, wird der Baustein an einer Stelle geändert — und gilt sofort in jedem Schriftsatz, der diesen Baustein verwendet. Keine veralteten Kopien in Einzeldokumenten. Keine abweichenden Formulierungen je nach Sachbearbeiter.
Bausteintyp | Funktion | Vorteil gegenüber Vorlage |
Argumentations-Baustein | Standardisierte Einordnung einer bestimmten Rechtsfrage | Zentral aktuell gehalten, einheitlich in allen Schriftsätzen |
Rechtsprechungs-Verweis | Zitat + Einordnung relevanter Entscheidungen | Verknüpfbar mit Beteiligtendaten-Referenzentscheidungen |
Einwendungs-Baustein | Standardreaktion auf typische Gegenargumente | Aus Erfahrung geformt, nicht ad hoc formuliert |
Status-Baustein | Formulierungen je nach Verfahrensstadium | Passend zum aktuellen Schritt im Workflow |
Variable-Baustein | Platzhalter für Aktendaten (Beträge, Daten, Namen) | Befüllt sich automatisch aus Fallvariablen |
Schicht 2: KI-Textgenerierung auf Basis der Aktendaten
Der KI-Textgenerator von DEPLAW kennt die Aktendaten. Er kennt die extrahierten Datenpunkte, die Verfahrenshistorie, den aktuellen Status. Auf dieser Grundlage generiert er den fallindividuellen Teil des Schriftsatzes: die Sachverhaltsdarstellung, die kontextbezogene Einordnung, die Verbindung zwischen den fixierten Textbausteinen und dem konkreten Fall.
Die KI füllt aus — die Bausteine geben die Qualitätsgarantie. Keine Halluzination bei den juristisch kritischen Formulierungen, weil diese in geprüften Bausteinen hinterlegt sind. Keine generische Sachverhaltsdarstellung, weil die Fallvariablen aus der Akte direkt einfließen.
Schicht 3: Rechtsprechungs-Einbindung über Beteiligtendaten
Die dritte Schicht verbindet Textgenerierung mit der Beteiligtendatenbank. Relevante Entscheidungen, die im System als Referenz hinterlegt sind, werden beim Schriftsatz-Entwurf automatisch vorgeschlagen — kontextbezogen, nicht als generische Literaturliste.
Das bedeutet: Wenn die Beteiligtendaten zeigen, dass in verwandten Verfahren eine bestimmte Entscheidung entscheidungserheblich war, erscheint sie als vorgeschlagener Verweis im Schriftsatz-Entwurf. Der Sachbearbeiter übernimmt sie, passt sie an oder verwirft sie. Er muss sie nicht recherchieren.
Das Schichtenmodell der Schriftsatzerstellung in DEPLAW |
Schicht 1 — Feingranulare Textbausteine: Juristisch geprüfte, zentral verwaltete Formulierungsbausteine für Standardkonstellationen — unveränderlich im Schriftsatz, bis sie zentral aktualisiert werden. |
Schicht 2 — KI-Individualisierung: Fallspezifische Sachverhaltsdarstellung, Einbindung der Aktendaten, Verbindung der Bausteine zu einem kohärenten Gesamttext. |
Schicht 3 — Rechtsprechungs-Kontext: Verknüpfung mit relevanten Entscheidungen aus der Beteiligtendatenbank — als vorgeschlagene Verweise, nicht als automatisch eingebettete Zitate. |
Schicht 4 — Menschliche Freigabe: Der Anwalt prüft, korrigiert, gibt frei. Kein Schriftsatz verlässt DEPLAW ohne diese Freigabe. |
Schicht 5 — Automatischer Versand: Nach Freigabe sendet DEPLAW automatisch — per beA, E-Mail oder Post, je nach Empfänger und Konfiguration im Workflow. |
05
Gesamtüberblick
Was strukturierte Massenverfahren-Automatisierung leisten kann.
Die drei beschriebenen Bausteine — automatische Fristextraktion, fallübergreifende Beteiligtendaten, intelligente Schriftsatzerstellung — sind nicht drei unabhängige Features. Sie sind drei Komponenten einer Architektur, die nur dann ihre volle Wirkung entfaltet, wenn sie zusammenwirken.
Manueller Massenverfahrens-Betrieb | DEPLAW-automatisierter Betrieb |
Fristen manuell aus Dokumenten lesen und eintragen | Automatische Extraktion beim Dokumenteneingang |
Erkenntnisse aus abgeschlossenen Verfahren nicht zugänglich | Beteiligtendatenbank macht institutionelles Wissen abrufbar |
Schriftsätze aus alten Vorlagen zusammenkopiert | KI-Generierung auf Basis Aktendaten + geprüfte Bausteine |
Qualität hängt vom Erfahrungsstand des Verfassers ab | Qualität definiert durch zentrale Bausteine — unabhängig vom Autor |
Rechtsprechungs-Recherche für jeden Fall neu | Verknüpfte Referenzentscheidungen aus Beteiligtendaten vorgeschlagen |
Skalierung durch mehr Personal | Skalierung durch bessere Prozessarchitektur |
Systemwechsel zwischen Postfach, Akte und Textverarbeitung | Vollintegriert — vom Eingang bis zum versendeten Schriftsatz |
Was diese Infrastruktur ermöglicht, ist nicht primär Geschwindigkeit — obwohl sie auch das liefert. Was sie primär ermöglicht, ist Zuverlässigkeit bei steigendem Volumen. Die Fehlerrate sinkt nicht, weil Sachbearbeiter sorgfältiger werden. Sie sinkt, weil die Schritte, bei denen Fehler entstehen — manuelle Datenerfassung, manuelle Fristnotierung, improvisierte Formulierung — durch strukturierte, automatisierte Prozesse ersetzt werden.
Relevante DEPLAW-Funktionen: Datenextraktion · Beteiligtendaten · Textbausteine · Textgenerator · KI-Funktionen · beA-Schnittstelle · Wiedervorlagen · Workflow-Editor